Ложь, сжигающая время: почему нейросети галлюцинируют по ссылкам и как NotebookLM спасает от фейков
Сегодня в очередной раз в общении с Gemini столкнулся с проблемой, которая меня бесит больше всего. Она тратит мое время, ресурсы и портит настроение.
Ты публикуешь сложный, выверенный материал, кидаешь ссылку в чат с ИИ и просишь сделать саммари или проверить логику. Модель мгновенно выдает гладкий, уверенный и профессиональный разбор. Вот только в нем содержатся факты, выводы и цифры, которых в твоем тексте никогда не было. Нейросеть просто врет, "глядя тебе в глаза".
Это не просто досадный баг или временный сбой. Это фундаментальная архитектурная проблема, из-за которой пользователи сливают лимиты (кредиты) впустую, принимают неверные решения и тратят часы на поиск ошибок там, где их нет.

Анатомия уверенной лжи: как на самом деле ИИ «читает» веб-страницы
Причина этой проблемы кроется в том, что разные LLM-платформы принципиально по-разному обрабатывают входящие URL. Нам кажется, что AI работает как браузер, но под капотом рынок жестко разделен на два лагеря:
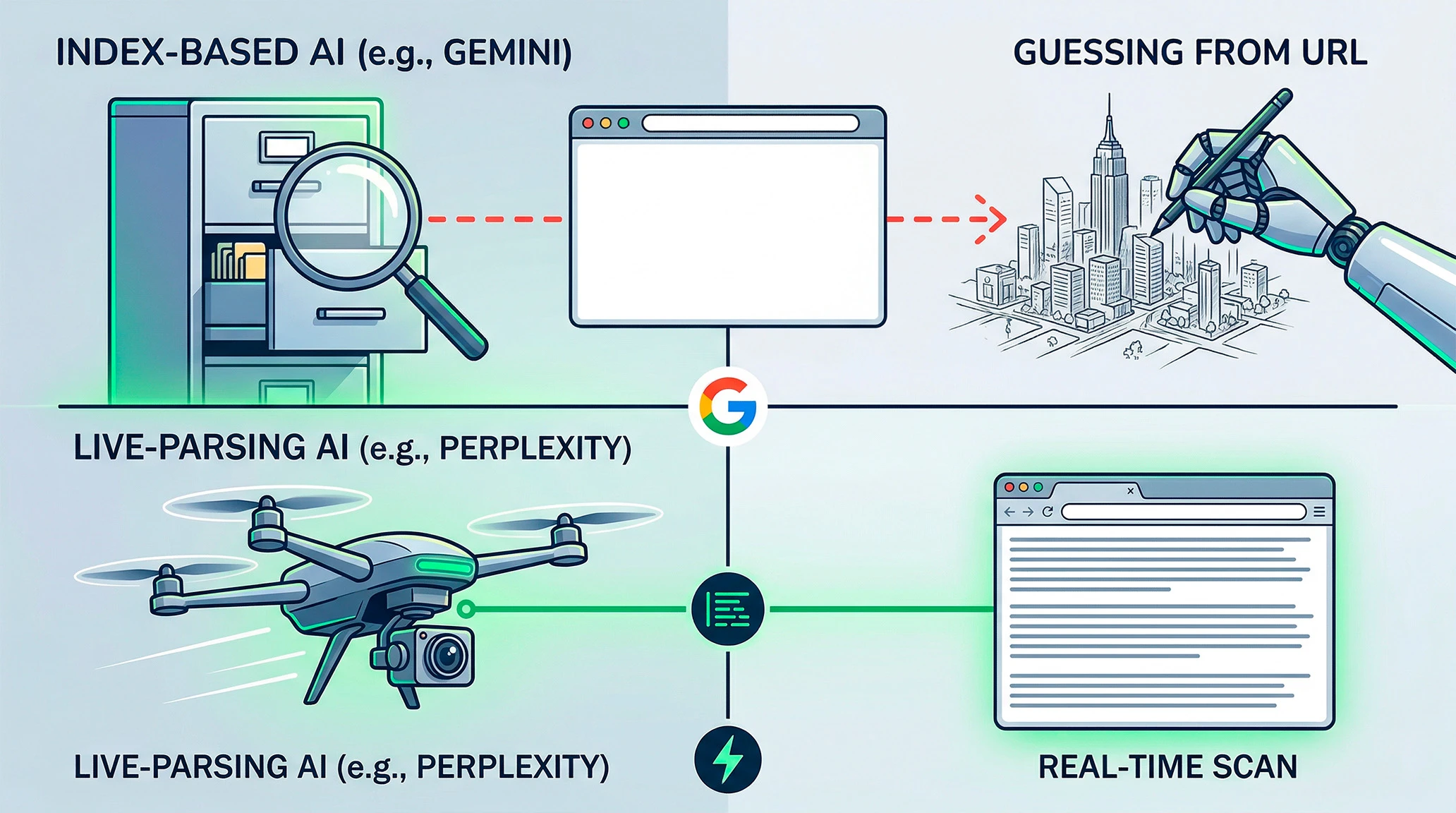
1. Live-парсеры (реалтайм-сканирование)
Такие системы, как Perplexity, изначально проектировались как поисковые агенты. Получив ссылку, они инициируют прямой HTTP-запрос (часто через headless-браузеры) и вытягивают DOM-дерево сайта прямо в момент вашего обращения. Если сайт не блокирует ботов, вы получаете анализ реального текста.
2. Индексные модели (экосистема Google / Gemini)
Ради экономии вычислительных мощностей и мгновенного отклика эти модели работают иначе. Они не идут на сайт. Они стучатся в кэш поискового индекса Google. И именно здесь захлопывается ловушка для создателей свежего контента.
Если вы отправляете ссылку на публикацию, которую поисковые роботы еще не успели обойти и закэшировать, индекс отвечает системе: Not Found.
Что должен сделать хороший инструмент в этот момент? Вернуть ошибку: «Извините, я не могу получить доступ к странице».
Но вместо этого включается скрытый fallback-механизм (сценарий отступления).
Чтобы не разочаровывать пользователя отказом, ИИ берет сам URL-slug (например, .../obzor-teable-alternativa), выявляет из него ключевые слова и запускает генерацию из своих базовых весов.
Результат? Система подсовывает вам высококачественную галлюцинацию. Она додумывает содержание статьи по ее заголовку в ссылке. Вы читаете этот бред, начинаете спорить с алгоритмом, тратите токены на уточняющие промпты — и всё это время обсуждаете текст, которого нейросеть физически не видела.
Как защитить свои данные и нервы в общении с искусственным интеллектом: изоляция контекста
Если вы работаете со свежими, конфиденциальными (закрытыми паролем) или неиндексируемыми материалами, скармливать публичные ссылки обычным чат-ботам — это напрасная трата времени.
Чтобы заставить языковую модель работать как точный аналитический инструмент, а не генератор сказок, нужно использовать жесткие ограничения RAG (Retrieval-Augmented Generation).
Самый быстрый способ получить такой уровень контроля в 2026 году — Google NotebookLM. И это можно сделать бесплатно.
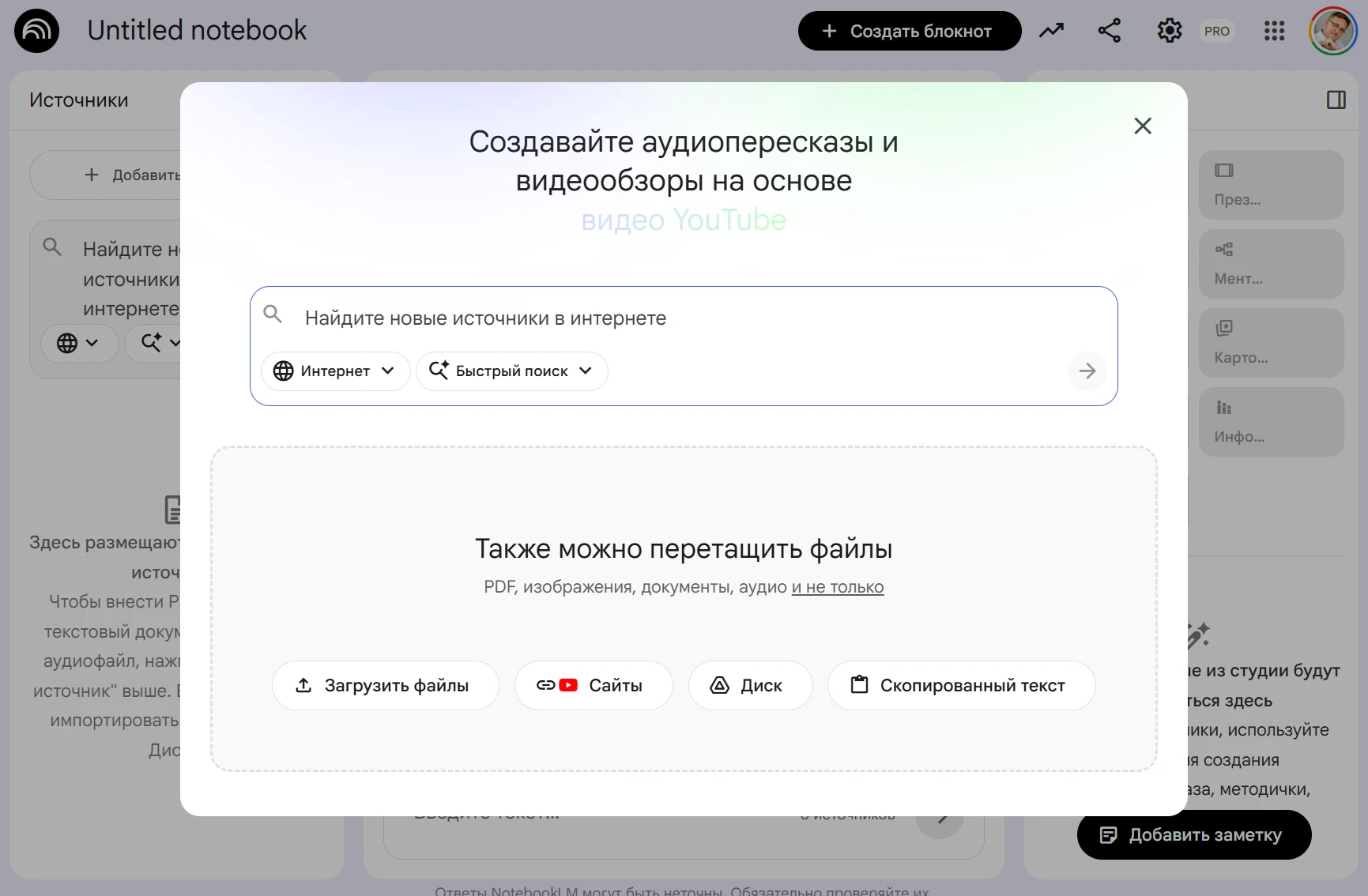
В чем кардинальное отличие?
NotebookLM спроектирован как "песочница" для ваших данных. Загружая туда исходный текст статьи, видео на youtube, PDF-файл или закрытый Google Doc, вы полностью отсекаете ИИ от публичного поискового индекса и попыток угадать контент по ссылке.
Система векторизует ваши файлы и строит локальную базу знаний. Работая внутри NotebookLM, вы не можете выйти за ее пределы. Встроенный чат-бот видит только добавленные вами данные. НО можно получить лучшее из двух миров, добавив созданный в NotebookLM блокнот в качестве источника данных в чате с gemini.google.com.
Алгоритм работы без галлюцинаций с моделями Gemini:
- Никаких сырых ссылок. Написали статью — не кидайте URL в общий чат. Загрузите исходник напрямую в NotebookLM.
- Если текст недоступен для сканирования - добавьте его в “ручном режиме” через функцию - “Вставить скопированный текст”

- Анализ. Система мгновенно сканирует загруженный документ.
- Жесткая привязка к фактам. В чате с Gemini прикрепите свой блокнот NotebookLM в качестве источника. Теперь вы можете задавать любые вопросы, просить найти несоответствия или составить посты для соцсетей. Каждое свое слово ИИ обязан подкрепить кликабельной цитатой-сноской из вашего оригинального текста.

Итог: давайте ИИ проверенные локальные базы данных
Доверять ИИ слепой анализ свежих ссылок — это непозволительная трата времени. Галлюцинации моделей обходятся слишком дорого, когда речь идет о проверке вашей реальной работы. Понимание того, как разные платформы парсят веб-страницы (через Live-запрос или через индекс), позволяет вовремя сменить инструмент. Если вам нужен честный анализ ваших фактов, а не фантазии на тему вашего заголовка — изолируйте контекст и работайте с локальными базами знаний.

Обзор Teable.ai: мощная альтернатива Airtable с AI и ловушка для кредитов в App Builder

🎙️ Как создать идеальный ИИ-клон голоса в 2026 году (и навсегда уйти от подписок)

SoundMadeSeen: как превратить аудио в видео с помощью AI и забыть о подписках. Личный опыт тест-драйва LTD-версии